一万小时 / 编译原理系列之词法分析
远没到拼智商的时候

编译原理系列之词法分析
对于每一具体阶段的学习记录,我想分为几个方面来加以阐述:此阶段的目标、 具体过程、重要工具、重要算法、关于实现、补充说明。
如此,各个方面相对具体,也显得条理清晰些。
词法分析的目标
如同在概述部分所说明的,词法分析即是将源程序(字符串)分割为token的过程,此过程中 会根据源语言的形式化定义,通过自动机等工具来判断是否源程序无词法错误,最终将由下一阶段 的输出是:
- 如果存在词法错误(通过自动机和语言的定义来判断),则显示词法错误,并停止编译
- 如果不存在词法错误,则向下一阶段输出一组处理后的token,及符号表。
当然词法分析另一个很重要的目的就是去除无关的元素,如whitespace(空格,制表符、换行符等)、 注释等,这样就可以省去语法分析阶段的相应工作、提高语法分析的效率和降低复杂度。
词法分析的具体过程
在说明过程之前,先说明几个重要的概念或者方法。
- token: 是由token class(或者也称为token class)和指向符号表的指针组成的一个组对(pair)
- Regular Expression:即正则表达式,是形式化描述语言的一种方法,日常中使用的语言如perl, python 等语言中的正则表达式即是此意,一个正则表达式匹配一种语言。
- 有限状态机:由状态和状态转移组成的一种工具,通常正则表达式的内部实现即是通过FSM来实现的;当然 在编译器的实现中,FSM也用作语言的匹配判断实现。
例如C语言变量的正则表达式为:
V = [a-zA-Z_][a-zA-Z0-9_]*
而此正则表达式的FSM为:
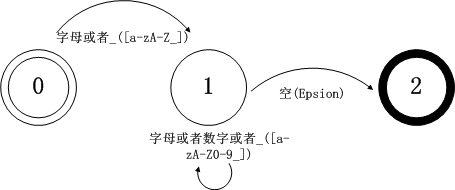
FSM也分为DFA(确定的有限自动机)和NFA(不确定有限自动机),DFA是一种特殊的NFA,特殊之处在于 同一个状态的出口转移边在面对同一输入字符时只能有一个。
相关的重要工具
有如下几个工具是需要说明和研究的:
- 词法分析器生成工具(也就是给定正则表达式,此工具可以生成相应语言的词法分析器)Lex
- FSM(有限状态机是CS中几个最为重要的工具之一,需要好好研究下)
具体工具的说明见词法分析中涉及的重要工具
相关的重要算法
有如下几个算法是比较重要的:
- KMP算法:即给定一个字符串s,和字符串t,判断t是否是s的字串,如果是则返回子串在s中的起始位置,否则返回-1
- 正则表达式到NFA的转换算法
- NFA到DFA的转换算法
具体算法的说明见词法分析中涉及的重要算法
相关的实现
相关的实现是基于C语言来完成,涉及到主要的算法的实现及一个简单的词法分析器的实现。
具体见词法分析相关实现
补充说明
词法分析过程所用到的技术(如正则表达式、FSM、KMP算法)等不只局限于编译器的编写,在CS的其它领域也有着广泛的应用, 如基于Python的文档撰写工具Sphinx中对于rst源文件的分析便用到了FSM,当然Sphinx可认为是将rst转换为html/latex/epub等 语言的编译器。