一万小时 / 编译原理系列之概述
远没到拼智商的时候

编译原理系列之概述
什么是编译
作为概述,当然首要是要说明什么是编译?单就这一问题,也是没有定论的,至少可以有 广义和狭义两个维度—— 狭义的编译自然是限制在计算机领域之内,是指将一种语言转换为另一种语言的过程。(当然 更加狭义的可以定义为编译是将一种高级语言转换为机器语言的过程。此处,我更加倾向于 前一种定义,当然语言是限制在计算机领域之内的)
广义的编译则已经跳脱出计算机的领域,所谓的语言也是广义的语言,例如将英语转换为中文 的过程,也可以称谓是编译。广义的定义也是将一种源语言转换为目标语言的过程,所不同的是 语言的范畴不再局限在计算机的领域。
关于编译范畴的讨论也是由来以久,例如hacknews上一篇关于Rich Programmer Food的讨论就 引出了关于编译定义范畴的讨论,在我看来争论的焦点还是范畴的考量,即上面提到的广义还是 狭义,就像广义和狭义相对论一样,如此2种的范畴考量也是没有问题的。当然一般的步骤自然是 先具体再抽象,先狭义再广义。
需要说明的是,本次的学习过程主要取狭义的定义和范畴,在结束时可能会大致讨论下广义下的相关 应用。(在下面的博文中,如果没有特殊说明编译即指狭义的范畴)
编译的过程
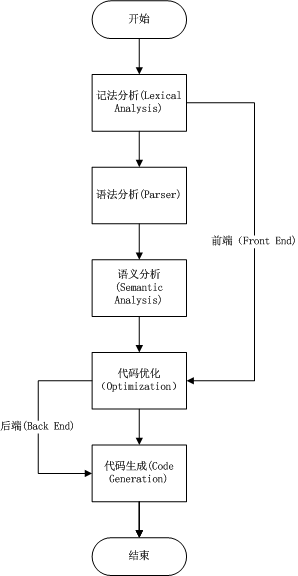
编译是一个复杂的过程,从它本身的元(meta)属性而言(我指的是它本身是创建软件的软件),它的 重要性不言而喻,自然也就决定了它的复杂性。大而复杂总是人类大脑的天敌,于是我们将其分为若干 个小而相对独立的过程(阶段),从而分而击之,各自研究,从而得出最终的全貌。
上面的图是一个非常简单的编译阶段示意图,已经略去了很多重要的细节,如符号表(symbol table), 控制流(flow of control)等,但当这几个阶段本身也大致已经涵盖了编译的主要环节。
下面的说明以如下简单的程序串为例:
if (a > 0) a = -a;
词法分析(Lexical Analysis)
词法分析是将输入的源语言串分割(partition)为token的过程,此处的token大致有如下的结构:
Token = <token class, attributes> 也就是包含着token class(如ID, Num等)和相应的属性。
如例子中的代码在词法分析后,可得到大致如下的结果:
- <keyword, “if”>
- <whitespace, “ “>
- <leftbracket, “{“>
- <ID, “a”>
- <whitespace, “ “>
- <RelOp, “>”>
- <whitespace, “ “>
- <Num, “0”>
- <rightbracket, “)”>
- <whitespace, “ “>
- <ID, “a”>
- <whitespace, “ “>
- <AssOp, “=”>
- <whitespace, “ “>
- <Op, “-“>
- <whitespace, “ “>
- <ID, “a”>
- <semicolon, “;”>
上面尖括号左侧的即为token class,右侧项为相应的属性(此处简化处理,实际中可能是指向符号表的指针)
当然这个过程可能会出现所谓“歧义”的现象(多种解释),如a=-a这个表达式,其中的“-”可以解释为 双目操作符减(substract)也可以解释为单目操作符取负(minus),如何消除这种“歧义”,于是便引入了 对于token的形式化定义,即通常的Regular Expression。
对于语言的形式化定义,则通常使用生成式(Production)来进行,如对于合法变量的定义:
- letter = [a-zA-Z]
- num = [0-9]
- L = [letter|_][letter|number|_]*
有了Regular Expression的形式化定义,则可以使用状态机来进行是否匹配的判断。这里面的状态机的作用则是 非常重要的,此处不细展开,具体可见词法分析的博文。
从而词法分析阶段便可以判断出源语言是否符合定义,如果不符合则可给出相应的出错信息,如果符合则给出相应 的token组。
语法分析(Parsing)
基于词法分析阶段的token,语法分析阶段则是构建出语法树的中间表达形式(Intermediate Representation), 而典型的语法树则是通常以操作符为中间节点,操作对象为叶子节点。
例如示例中的代码的语法树可表示为:
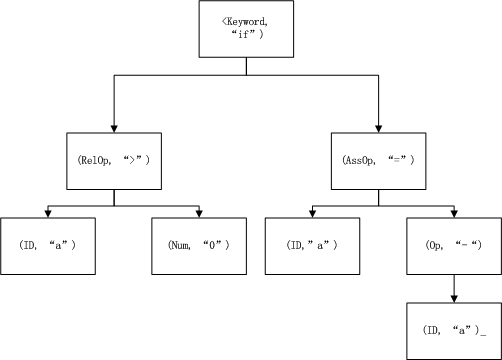
当然除了语法树外,还有其它的IR表达方式,如三址法:
- if a > 0 goto 2
- a = -a
语义分析(Semantic Analysis)
语义分析是基于语法分析生成的IR,用于检查语义层面上是否符合语言的定义,例如类型检查。
例如: x = 1.5 * 3
在语义分析阶段会进行类型检查,从而将3根据语言的定义(*的操作对象类型应该相同,语言层面的向上类型提升) 转换为3.0。即由int转换为float或者double
当然,语义层面的检查是困难,目前也只能作一些有限的简单的工作(如类型检查)。提了很久的语义网络是缓慢发展 也说明了语义分析的困难性,当然这是一类的问题,即机器理解语义(AI),像机器翻译、自动文摘、语音识别等 大致也可纳入此类。
代码优化(Optimization)
代码优化是目前编译领域研究的最前沿,也是最为重要的,主要有几个原因:
- 程序员之所以使用高级语言,即是因为编译后的代码与手工写的低级语言(汇编)几乎是同一量级的优化程度
- 即使摩尔定律下的硬件发展,无论何时资源总是有限的
- 无论是编译时的优化或者运行时的优化(JIT),用户看到的即是优化后的程序,而直面用户的也总是最挑剔的
所以whale book大部分内容讲的即是优化的过程。
优化可能会包括:中间变量消除,循环优化等。
代码生成(Generation)
在语义分析和代码优化后,我们仍使用的是语法分析后的IR,而代码生成阶段则是将IR转换为特定机器的机器 码。通常生成特定格式的汇编语言,当然也包括存储器的分配等内存管理方面的问题。
代码生成阶段所生成的代码也不尽相同,例如可以生成汇编语言(更加灵活)、absolute机器语言、relocable机器 语言等。当然,越是灵活的生成代码(如汇编、relocable code),会在后续有更多的处理(如汇编器、动态链接等)。
总述
如图中所示,词法分析、语法分析、语义分析构成了编译器的前端部分(Front End),而代码优化和代码生成则构成了 其后端部分(Back End)。著名的编译器如GCC,则是提供了整套的解决方案,即同时提供前端和后端;而由苹果主导的 LLVM所提供的后端以及不同的前端实现(如CLang)构成了更加灵活的编译框架,前后端的耦合更少,相应的前后端的 效率更高。这也就解释了为什么随着iOS的发展,XCode的不断进化,苹果推荐的编译从GCC->GCC(前端)+LLVM->CLang+LLVM 的组合。