一万小时 / APUE读书笔记1
远没到拼智商的时候

APUE读书笔记1
File Descriptor
File Descriptor: 文件描述符,通常是一个int(long),可分配的FD也是有限的 (int/long的大小, 内存大小等),ulimit -n可以查看。
对于此,想到了几个之前的问题:
- mysql有个open-files-limit参数即是设置可以打开的文件数(可申请的FD数)
- 水木上有人提到绕过OS和TCP/IP协议栈模拟10M请求的讨论,也是部分因为 FD的OS限制
System call/Library
OS会提供一定的System call,而特定OS的library则是基于System call的实现, 一个library function可以使用1+个system call来完成特定的功能。 作者的一个例子,malloc是library function, 而其使用system call sbrk 来 实现kernel的具体操作。我们也可绕开library,而实现自己的内存管理libary,但 仍需要调用 system call的 sbrk (brk/sbrk是通过更改break value来实现内存 的调整,brk means break)
user process的application code既可以调用system call,也可以调用library 来实现相同的功能,library是对system call的补充和封装。
Standardization标准化
主要有几个标准化努力,包括ISO C, IEEE POSIX, Single Unix Specification.
主要的Unix(alike)系统都是支持几个标准的,但一些定义对于不同机器有不同的 定义,包括编译时可确定的如limits.h,或者运行时可确定的需要sysconf,pathconf, ppathconf来运行时确认;有一些可选的功能也可通过编译时和运行时检测来确认 是否host machine支持此功能。
File IO
Unbuffered IO, 是指每一个read/write操作对应一个system call, 与standard IO不同。
共有若干个call,分别是 open, creat, close, lseek, read, write
比较新的Unix支持O_CREAT作为open的mode,此时creat显得多余。
close会释放process占有的相关record lock,但是一旦process退出、结束, 相关的FD会被自动释放,所以有些程序,并不显式close FD
由于多个进程可以操作同一个文件,因而文件的share机制很是重要,unix的机制 如下:
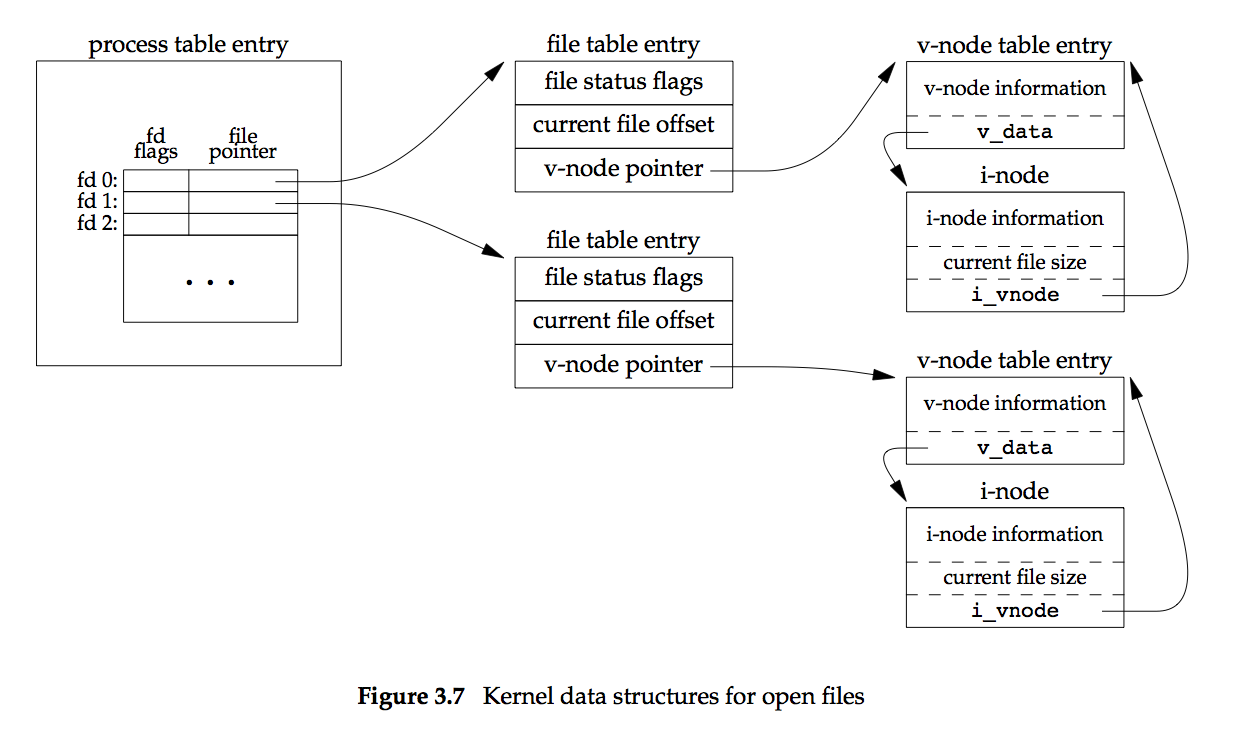
当2个进程打开同一文件时,机制如下:
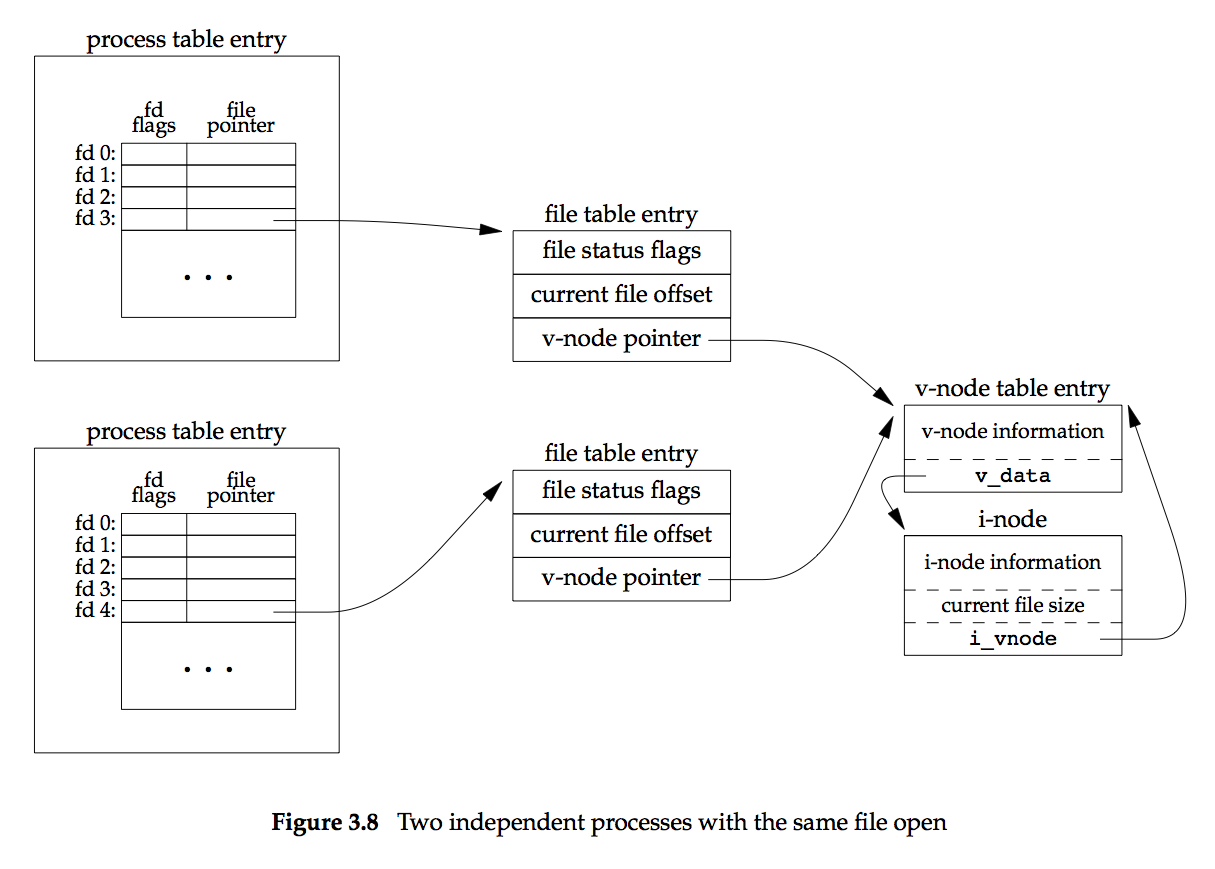
当多个进程读同一文件时,不存在竞争的问题,但涉及到多个写时,为了保证写的 正确(进程的写时间),则需要所谓的“原子操作”。
对于write, O_APPEND可以保证seek到文件end和写是原子操作。
更改FD, 可通过dup, dup2, fcntl来完成。
在write时,写的blocks并不会实时写入disk中,而是会cache一定的时间,如30秒, 如果需要保证写能够实时写入disk,则可通过fsync,fdatasync来完成,sync会同步 所有cache的blocks.
文件与目录
在Unix下,所有的资源都可作为file来看待。
当要打开一个文件,需要保证文件名中的所有中间目录有execute的权限,包括当前 目录,而对于文件本身需要根据open的mode来确认是否有相应的权限。注意一个目录 的execute权限与read权限是不同的,前者是指当目录作为pathname时可搜索的权限, 而读是指可以获取目录中所有文件filenames的权限。
一个文件可以有多个directory entry指向该文件的i-node,使用link/linkat函数 可以创建一个link给一个存在的文件,一个i-node有个link count属性标记这个 文件的link次数,只有当link count=0,才能删除。所以Unix中删除一个directory entry称作unlink而不是delete.
对于rename(mv),实际的实现通常是增加一个directory entry来指向文件的i-node, 然后删除rename前的directory entry, i-node的link count保持不变。
unlink后如果文件的link count=0,但是已经是打开的,那么directory entry会删除 (ls看不到),但相应的data block不会释放/删除,当打开文件的进程结束,kernel 会检查文件的link count,如果等于0,则释放相应的data block。
remove函数对于regular file,等于unlink,对于directory,等于rmdir, 比较而言, unlink的含义更准确。
Standard I/O Library
与Unbuffered IO主要基于FD不同,Standard IO主要基于stream,当我们使用Standard IO 打开或者创建一个文件时,我们便将stream与这个文件关联起来。
Standard I/O有3个预定义的stream,分别是stdin, stdout, stderr,定义在
- stdin/stdout必须是完全缓存的,除非指向的是一个可交互的设备(an interactive device)
- stderr必须不时完全缓存的
在常见的Unix/Linux中,通常的实现如下:
- Standard error is always unbuffered
- All other streams are line buffered if they refer to a terminal device; otherwise, they are full buffered.
可以通过setbuf/setvbuf来更改默认的缓存规则,总共3中缓存规则,即full buffered, line buffered, no buffered.
我们也可以调用fflush来flush缓存。
fopen以a+打开时,必须要保证实现时使用O_APPEND标志,而不是首先lseek到文件尾,再append,因为 这是2步,不是原子操作,有可能与预期不一致。
读写:
- getc/fgetc/getchar/ungetc, 读取或者“回写”一个字符,其中getchar=getc(stdin)
- putc/fputc/putchar: 写一个字符, putchar(c)=putc(c, stdout)
- fgets/gets, 其中不要使用gets,因为无法制定lenght, 就有可能引起buffer overflow,通常会被 用来最为病毒或者蠕虫来攻击。
- fputs/puts, puts是安全的,但是与fputs不一样,他会自动添加一个newline,而fputs/fgets需要我们处理newline
- fread/fwrite通常用于处理binary file,
binary file不能用getc/putc/fgets/fputs等来处理,因为在binary file每个byte可能含有null,而面向字符的 读写函数可能会因此而认为结束。 binary file的通常没有特定的结构,因为对齐方式等,以及编译器、操作系统的差别,所以binary file通常不能跨 OS使用,甚至同一OS由于不同的对齐设定,也可能会有问题。只有约定号结构,才能够保证跨平台的binary file。
确定文件当前stream的位置,可以使用ftell/fseek/rewind,因为其中的fseek中的offset参数是long,所以对于 一个大文件,fseek可能无法达成相应的功能,所以有ftello/fseeko使用off_t类型,其可以定义大于long的长度。
另外ISO C定义了fgetpos/fsetpos函数其中使用fpos_t来指示pos的大小,而fpos_t可以定义为足够大。
格式化输出可以使用printf/sprintf/dprintf/snprintf几个函数,其中sprintf由于未指定buf大小,所以可能会溢出, 建议使用snprintf.
类似的格式化输入可以使用scanf/sscanf/dscanf/snscanf.
ISO C还提供临时文件的帮助函数,tmpnam, tmpfile
Standard IO有性能上的不足,Korn和Vo指出了其中的几个问题,例如:fgets/fputs存在2次拷贝,即一次是kernel和standard io 的buffer,一次是standard io和我们自己的line buffer, 于是有了fast IO
Chap6. System Data Files and Information
nobody用户通常有65534的uid和gid,允许用户登陆,但没有任何权限。
/etc/passwd通常存储用户的登陆信息,如用户名,uid,gid,password,shell等,由于安全原因,此文件通常不存储password, 而是将实际的加密密码存储在/etc/shadow中,称为shadow password,此文件通常只允许root来读写(login, passwd命令)。
使用who/last命令可以查看当前的和历史的登陆记录。
date/time相关的函数基本上在不同的语言中都有类似的实现,如python等。
Chap7. Process Enviroment
退出一个进程通常有如下几种办法:
- return from main
- calling exit (exit会做额外的清理工作,如fclose已经打开的stream)
- calling _exit or _Exit
- return of the last thread from its start route
- calling pthread_exit from the last thread
- calling abort
- receipt of signal
- response of the last thread to a cancellation request
exit(status_code)返回一个状态码并返回,可以使用atexit 来注册退出前的exit handler, ISOC 规定至少可以注册32个exit handler,注意调用的顺序与注册的顺序相反。
通常一个C程序在内存中有如下几个部分组成:
- text segment: 包含CPU执行的机器指令,通常text sgement可以在不同的程序中共享,而且通常也是read-only的
- initialized data segment, 也叫data segment, 包含程序初始化的数据,例如不属于任何函数的定义int a=99
- uninitialized data segment, 也叫bss(block started by symbol,源于assmbler),此段内的数据被kernel初始化为0或者空指针,如 不属于任何函数的声明 int a[20]
- stack, automatic variable存储于此,函数中的自动变量、临时变量在函数运行时动态申请栈空间(stack frame),每次的调用都是申请 新的stack frame,所以C中的递归是可行的,且互不干扰。
- heap, 动态申请的内存通常存储于此,如使用malloc申请的,historically, heap通常位于uninitialized data和stack之间。
一个典型的内存分布如下:
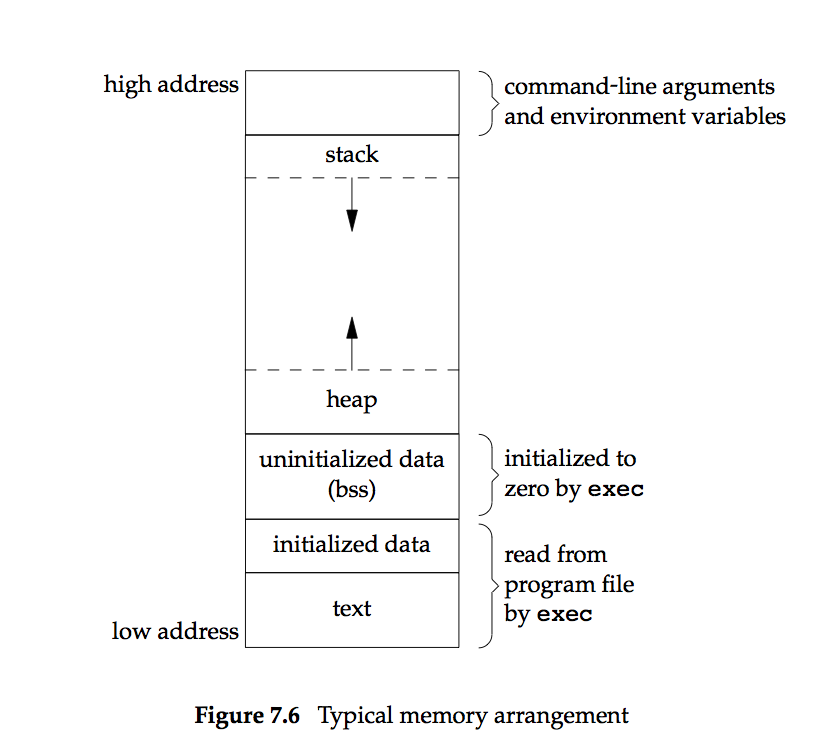
对于一个程序,只有text segment和initialized data需要存储在disk上,其它则在运行(开始或者过程中)进行分配。
shared library可以较小程序的空间占用,但可能会在首次加载和调用时会有overhead,对于使用静态链接的程序通常text segment/data segment 都会更大,例如使用gcc -static hello.c(静态)和gcc hello.c(动态)
动态申请内存,可以使用malloc/calloc/realloc,释放时使用free. realloc可以动态增加或者减少内存,但通常只是增加,例如对于一个数组,我们 开始申请了500个char的大小,运行时发现不够用,则我们使用realloc又申请了200个,此时如果之前申请的500个char的内存区域还有足够200个char 空间则直接获取相应的空间,并返回传入的指针,否则,在一个足够500+200的空间获取空间,并将之前申请空间(500)拷贝到新的空间,并释放之前 申请的空间,返回新区的指针。
对于free,释放的空间并不会返回给kernel,而是返回给malloc pool,来供后续的alloc申请内存。申请内存通常是通过调用sbrk(kernel call)来进行 实际内存的申请和释放。通常malloc会申请对于参数要求的大小,额外的空间用于record-keeping information(如block size, 下一个可分配block的地址等) 存储,所以读写申请参数范围外的内存通常不会出错,这样的错误会很难发现。
环境变量
可以通过getenv和setenv来获取和设置环境变量,运行时设置环境变量不能更改父进程的环境变量(例如程序运行于shell,程序不能更改shell的环境变量)。
函数内跳转可以使用goto,函数间跳转可使用setjmp/longjmp,其中setjmp设置跳转点,longjmp进行跳转,调用longjmp会清除相应的嵌套stack frame。 nonlocal jump(也就是这里的longjmp),跳转回来后相应的变量值是调用时变更的值,还是初始时的值,取决于实现,一个规则是 :
one system states that variables stored in memory will have values as of the time of the longjmp, whereas variables in the CPU and floating-point registers are restored to their values when setjmp was called.
当然这个规则也是实现相关的。为此,为了一致的表现(跨系统),我们通常使用volatile 变量来保持初始值。